- Understanding the Scope: Assess your data sources and define the objectives of your project migration.
- Planning and Preparation: Establish a clear plan, and identify which data is critical to your business.
- Execution: Follow our step-by-step guidance on effectively migrating and validating data.
- Post-Migration Review: Validate our checklist of best practices for ensuring data integrity, migrating saved entities, and addressing any issues that arise.
When project migrations may be needed
There are various reasons why you may want to complete a project migration.- Security and Data Access
- You want to better govern data access in Mixpanel. Consolidating data into one Mixpanel project and leveraging our features such as data views and data classification can ensure that only users with the correct permissions can view certain data.
- Identity Management
- Addressing identity management issues and resolving problems related to defining unique users across projects.
- Group Analytics
- You have existing project data that does not contain the group key data that you need in order to run your analysis. You need to backfill group key data on historical event data.
- Messy data
- Your organization has been relying on a legacy project for quite some time, but the data has become increasingly difficult to use. You’re looking to create a streamlined, more efficient version of the project while ensuring you can retain the valuable data that is still actively utilized by your organization.
- Consolidating siloed data
- You have data in multiple Mixpanel projects based on product, platform, or location, but would like to consolidate the data to ensure analysis can be done cross-product, cross-platform, or cross-location.
Establish Scope & Key Stakeholders
To better understand the goals of investing in a project migration, it’s best to define the scope and objectives upfront with key stakeholders. 1. Define the Project Scope- Objectives and Goals:
- Clearly state the objectives of the migration. What are you aiming to achieve? This could include consolidating data in one place, improving data governance, etc.
- Identify what is in scope for this migration. Do you want to bring all data from all projects into one or select a subset of data to retain?
- Timeline and Milestones:
- Create a high-level timeline that outlines key phases of the migration, such as planning, execution, validation, and post-migration review. This will help keep the project on schedule.
- Best practice: For larger migrations, the planning phase can become more complex. Using a phased approach to break down the data migration process, with multiple QA checkpoints along the way, helps identify and resolve issues early. This approach reduces the risk of discovering problems in later stages and minimizes the need to reimport quality improvements in subsequent phases.
- Create a high-level timeline that outlines key phases of the migration, such as planning, execution, validation, and post-migration review. This will help keep the project on schedule.
- Identify key points of contact upfront:
- Project Manager: Point of contact responsible for developing a detailed project plan that includes scope, objectives, timelines, and resources. Engage with stakeholders to understand their requirements and expectations. Regularly communicate progress, risks, and issues to ensure everyone is aligned and informed.
- Key Product Stakeholders: Point of contact responsible for documenting established KPIs and the product-specific requirements for the data migration. Ensure that the data migration aligns with the overall business goals and objectives of the team. Provide input and feedback on the migration plan and give final approval on data mapping and transformation to ensure that the product team can clearly understand and utilize the ingested data.
- Key Data Stakeholders: Serve as the primary contact for defining data migration requirements, including what data needs to be migrated, how it should be transformed, and any specific constraints or needs in order to report on product’s established metrics. Ensure that the migration team has the necessary data access for each required tool. Assist in assessing and validating data quality, including identifying and resolving issues such as duplicates, inconsistencies, or errors.
- Executive Buy in: Gaining strategic alignment is imperative to the success of this project. This point of contact is responsible for ensuring the data migration initiative aligns with broader business goals. Without it, there’s a risk the project could be deprioritized, leading to delays or incomplete execution.
- Feedback mechanisms, such as having Project Managers create a shared project plan where stakeholders can stay informed about progress, decisions, and issues, can help generate greater visibility throughout the project migration process. Example Data Migration Project Plan
Steps
Step 1: Create New Project
Go to your Mixpanel UI, select the project down-drop at the top left-hand corner of your window, and select “Create Project.” In your Organization settings navigate to the “Identity Merge” tab. There will be a “New projects in this organization will default to” drop-down, ensure this is set to “Simplified API”.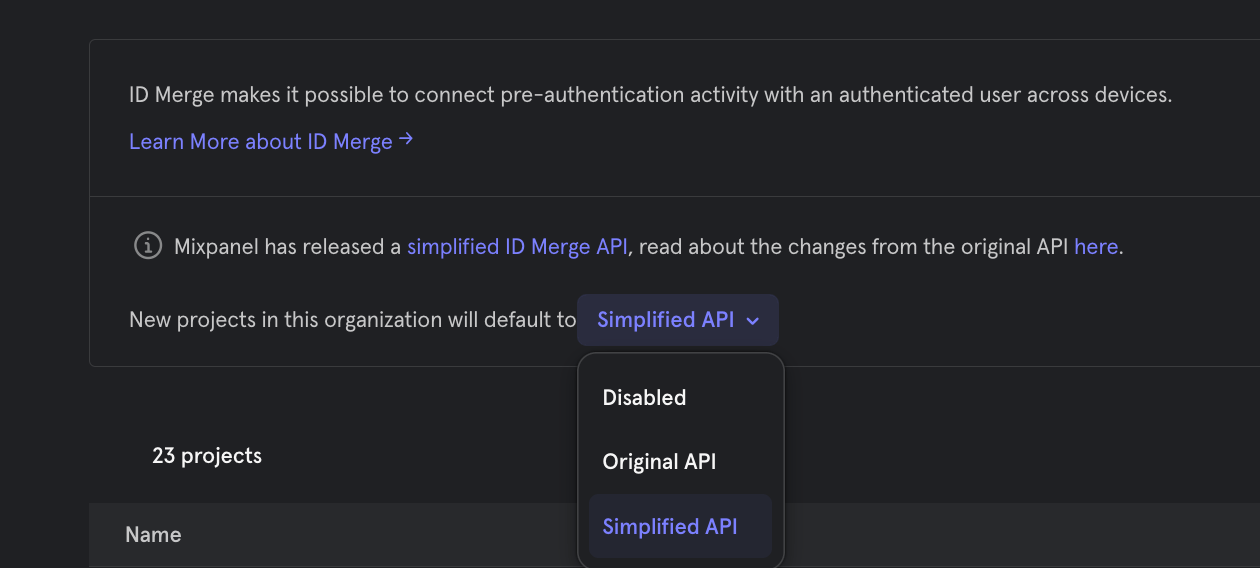
Step 2: Data Audit
Conducting a thorough data audit is essential for a successful project migration. By systematically reviewing and assessing your data, you can ensure that only the most relevant and high-impact information is transferred. Follow these steps to audit your data effectively and streamline your migration process: Prioritize Current Uses Cases:- Your project Lexicon provides insight into the number of UI and API queries performed by end users over the past 30 days. Focus on consolidating a list of events and properties where the “30-day queries” count is greater than 0. Prioritize migrating only the data that is actively being queried or has a clear, measurable business impact.
- Build out a reverse spec that is inclusive of only the events/properties being utilized today. You can export your Lexicon data dictionary from the legacy projects as a starting point for the reverse spec. Be sure to note which events and properties will be retained for the new project as your metrics and business needs become formalized.
- If you haven’t done so already, consider running an analytics strategy session to develop a framework of KPIs and identify the events and properties that are needed to unlock this analysis.
- Using the reverse spec built above, denote the events and properties that enable the analysis of each KPI deemed important during your analytic strategy discussion. If none of the events and properties in the reverse spec can be used to report on a KPI that was surfaced in the analytics strategy, scope out events and properties that would be needed in the next sprint to achieve this analysis.
- Conversely, if events and properties are included in the reverse spec but are not being used to measure any KPIs from your strategic discuss, determine if these events and properties are crucial to your analysis or if they can be removed from tracking.
- When merging multiple projects, review the event and property taxonomy across all projects to identify opportunities for consolidation during the ETL process. This can help reduce the number of events and properties being transferred to the new project, streamlining the dataset and improving overall efficiency. This includes data type conflicts, inconsistent naming conventions, duplicate/missing values, and identity management strategies. When comparing the data schemas of the projects being migrated, ensure that key event and property names align and that there are no conflicts in data types, structures, or naming conventions.
-
Once these key steps are complete you should have a clear & explicit set of events & properties in scope for this migration. As well as established requirements around how far back you expect the data to go, which user identifier will define uniqueness, and an established naming convention to avoid type conflicts moving forward.
💡 Best practices for scoping data:
- Only migrate events and properties that are being actively utilized to avoid cluttering your project data.
- Mixpanel only retains data for up to five years. It is worth surveying your team to understand time intervals of the metrics most important to them as to not bring over years of data that may go unused.
Step 3: Export Existing Data
Once you have determined how far back your data requirement is you can export this data via our Raw Export API or, if your organization has our Data Pipelines add-on, you can leverage the data you already have in your data warehouse. We recommend exporting a raw pipeline, as opposed to a schematized pipeline, this will export events as JSON to a cloud storage bucket. With the raw data export API you can export all event data as the ‘event’ parameter is optional. See example request below:- The API will allow for a maximum of 100 concurrent queries, 60 queries per hour, and 3 queries per second.
- If your original project was created prior to March 2023, time should be converted to UTC.
event or where parameters to query for the specific event data you’re looking to migrate.
Step 4: Transform Data
Upload the exported event data to your storage object, the process here may vary depending on the data warehouse you use. Our warehouse connector supports integrations with BigQuery, Snowflake, Databricks, and Redshift. Checklist before running transformations:- Compare the timezones from your existing projects to the new project to determine any timezone offsets that are necessary
- Understand if any transformations are required to uniquely identify your users
- Determine a To/From Date
- Add a group identifier if you’re looking to backfill analysis on a group analytics key.
- Add a super property to utilize data views to leverage access to a subset of data for a group of users within a single Mixpanel project.
Step 5: Import Data
Once your event table/view is formatted as expected, navigate to the new project you created in Step 1 in your project settings and connect your warehouse source to Mixpanel. Find your table/view in the drop-down settings and map your fields accordingly. Setup Source: find your source Dataset: find your dataset Table/View: find your table/view Map Columns:Default Event
Event Name: Select the ellipsis and choose Map to Column select event_name
Event Time: event_time
User ID: user_id (this will serve as your canonical ID)
Device ID: anonymous_id (this will serve as your pre-authenticated ID)
+Add Mapping Button: Select JSON Properties and select properties
Sync Settings
Sync Mode: Append (if you’re actively sending data to Mixpanel otherwise you can select One Time)
Insert Time: mp_processing_time_ms
If you are not leveraging our warehouse connectors offering, you can use our import API instead. Review the GCS batch import script below and modify it to suite your needs (i.e. If your project is stored in the EU adjust your API endpoints accordingly):
(Optional) Step 6: Export Users
This step is optional if you would like to migrate historical user properties into your new project. If you have our Data Pipelines add-on you can use the user table in your data warehouse. If you do not have access to this user profile data outside of Mixpanel, you can utilize the python script below to export user profile data. Runpip install mixpanel-api in your command line
(Optional) Step 7: Transform Users
Using the imported user data in your data warehouse, you can build out logic in SQL to create a view to pull specific data in or import your table as is. Example SQL logic to build out transformations to import as user profiles in Mixpanel:(Optional) Step 8: Import Users
Once your user table/view is formatted as expected navigate to your new project, head over to your project settings and connect your warehouse source to Mixpanel. Find your table/view in the drop-down settings and map your fields accordingly. If you have not purchased warehouse connectors, you can leverage our Engage API instead. Here’s some sample code to get you started, utilizing the$set operator to update user profiles:
Step 9: Redirect Project Data
Update the project token for platforms actively sending data to Mixpanel today. If any ETL work was completed during the migration to consolidate events and properties or change unique identifiers, make sure your implementation incorporates these changes. This will ensure that all new data streaming into your project aligns with the migrated data.Step 10: Data Validation
1. Post-Migration Data Quality Checks- Count Verification: After the migration, verify that the number of events (totals & uniques) in the migrated dataset matches the expected total. This can be easily verified using our Insights report. Any discrepancies should be investigated and resolved.
- Data Consistency Check: Ensure that the data is consistent across all events. For example, verify that all related properties have been correctly migrated and that no data types, or naming convention conflicts exist.
- Unique Identifier Validation: Check that all unique identifiers remain unique after the migration and that no duplicates have been introduced.
- Collaborative Validation: Involve key stakeholders, such as data owners, project managers, and end-users, in the validation process. Their insights can help identify potential issues that automated checks might miss. Ensure they can pull the KPIs they’ve identified as critical in the analytic strategy discussion. Document the KPI in a shared board and how you gained this insight for future reference.
- Pro tip: Creating a reference guide at this step can serve as a helpful guide as you socialize the new project with end users getting up to speed at your organization.
- Feedback Loop: Create a feedback loop where stakeholders can report any issues or concerns after reviewing the migrated data. This feedback is essential for making final adjustments.
- Obtain Sign-Off: Before the migrated data is put into production, obtain formal sign-off from all relevant stakeholders to confirm that the data has been validated and meets the necessary standards.
Step 11: Migrate Saved Entities
Saved entities, such as reports, boards, custom events, custom properties, cohorts, and lexicon metadata, are critical components that provide valuable insights and streamline workflows. During a project migration, it’s essential to carefully migrate these entities to ensure continuity and maintain the integrity of your analyses. Steps for Migrating Saved Entities:- Inventory and Categorize Saved Entities:
- Begin by creating a comprehensive inventory of all saved entities in each project. Categorize them by type (i.e. boards, reports) and by their usage frequency and importance.
- Identify any duplicate or obsolete entities that may not need to be migrated, streamlining the overall process.
- Map Saved Entities to the New Project Structure:
- Review how saved entities relate to the data model and taxonomy in the new project. Update or adjust entity configurations as needed to align with the new structure.
- For example, if event names or properties have been consolidated during the ETL process, ensure that these changes are reflected in the saved entities.
- Review how saved entities relate to the data model and taxonomy in the new project. Update or adjust entity configurations as needed to align with the new structure.
- Migrate Entities in Phases:
- Consider migrating saved entities in phases, starting with the most critical and frequently used ones.
- Engage key stakeholders to review and validate the migrated entities, as their input can help identify any issues that might have been missed.
- Update Documentation:
- Update any documentation related to the saved entities to reflect changes made during the migration. This includes updating success plans, reference guides, and any other resources that refer to these entities.
- Communicate with End Users:
- Notify end users of the migration and provide them with any necessary training or resources to understand changes in the saved entities.
- Offer support channels for users who may encounter issues or have questions about the migrated entities.
- Prioritize Key Entities: Focus on migrating the most important and frequently used entities first to ensure critical business functions continue uninterrupted.
- Collaborate with Stakeholders: Involve key stakeholders throughout the migration process to ensure that their needs are met and that the migrated entities align with their expectations.
- Boards & Reports: Utilize Move to transfer saved boards and reports across the same region (i.e. US, EU data centers). Permissions are managed by group admins allowing Boards to be moved across Projects or Organizations, depending on your use case.
- Move does not support the migration of custom events, custom properties, cohorts, and lexicon metadata. This would need to be done manually. Review these lists with stakeholders and decide if any of these saved entities would need to be recreated in the new project to set your end users up for success.
- Lexicon metadata can be retrieved from existing projects and recreated in the new project via our Lexicon Schemas API.
Ongoing Optimization
As organizations grow and new use cases become available to become analyzed it presents an opportunity for data to drift from the governed processes we put in place throughout this playbook. Having a process in place for new teams to follow allows for your customer to scale cleanly. Leveraging our in-product data governance tools can help support ongoing structure throughout your customers projects. Implementing the use of “verified” metrics, events, and formulas helps end users identify trusted content across the organization. Once your trusted governance owner(s) verify content, a blue checkmark badge will be displayed in the query builder as well as within a dedicated category within the query builder to help users quickly filter to see only trusted content. Having pinned and favorite boards for new users to jump into as they familiarize themselves with the data is a great place to start. We see the most success when companies have a trusted metrics board for each team or product that leverages this. These boards not only guide users in exploring new use cases but also ensure they leverage the correct events and properties to get the answers they need. Our in-product data standards tooling empowers your organization to scale your data operations by acting on your data at scale through the a rule based system. Today, you can define the following standards:- All my events must be [X] case
- All my events must include a description
- All my events must include an owner