Amazon S3
This guide demonstrates how to set up a serverless ingest pipeline from an AWS S3 bucket into Mixpanel. Once this is set up, you can simply upload files containing events into the designated S3 bucket and the events will be ingested into Mixpanel, both one-time and on a recurring basis. Setup should take ~5-10 minutes.
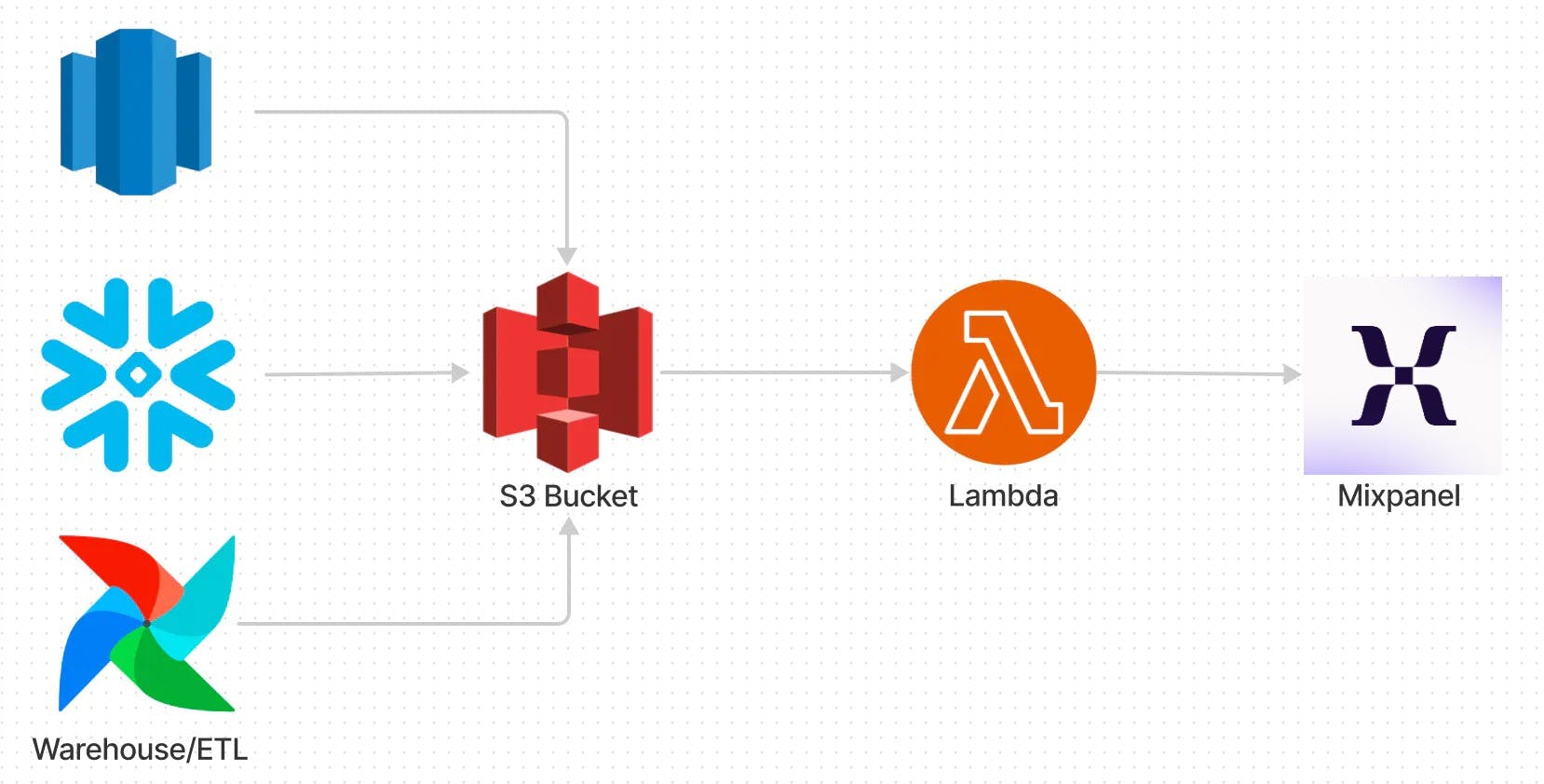
Note: This guide assumes you are running in Amazon Web Services, and have the necessary IAM Access to have AWS Lambda read from S3.
Step 1: Create an S3 Bucket
Create a dedicated S3 bucket for this integration. We recommend including mixpanel-import in the name to make it explicit and avoid any accidental data sharing.
You can create the bucket in any region, though it will need to be in the same region as your AWS Lambda function.
Step 2: Setup Import Config
Step 2a: Setup the Lambda Function
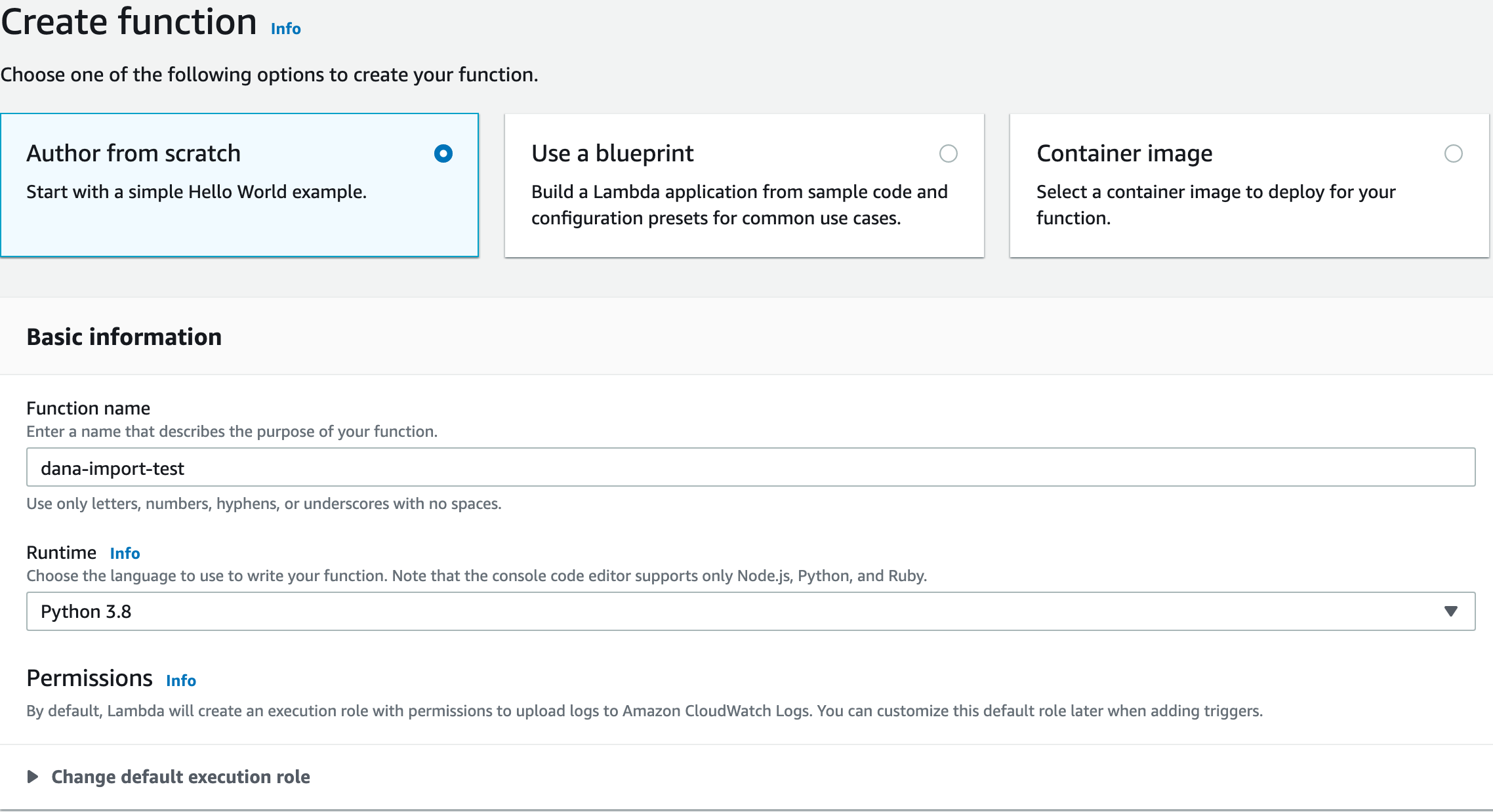
Create a new Lambda Function.
- Select
Author From Scratch. - Select a Python runtime.
- Select
Create Function.
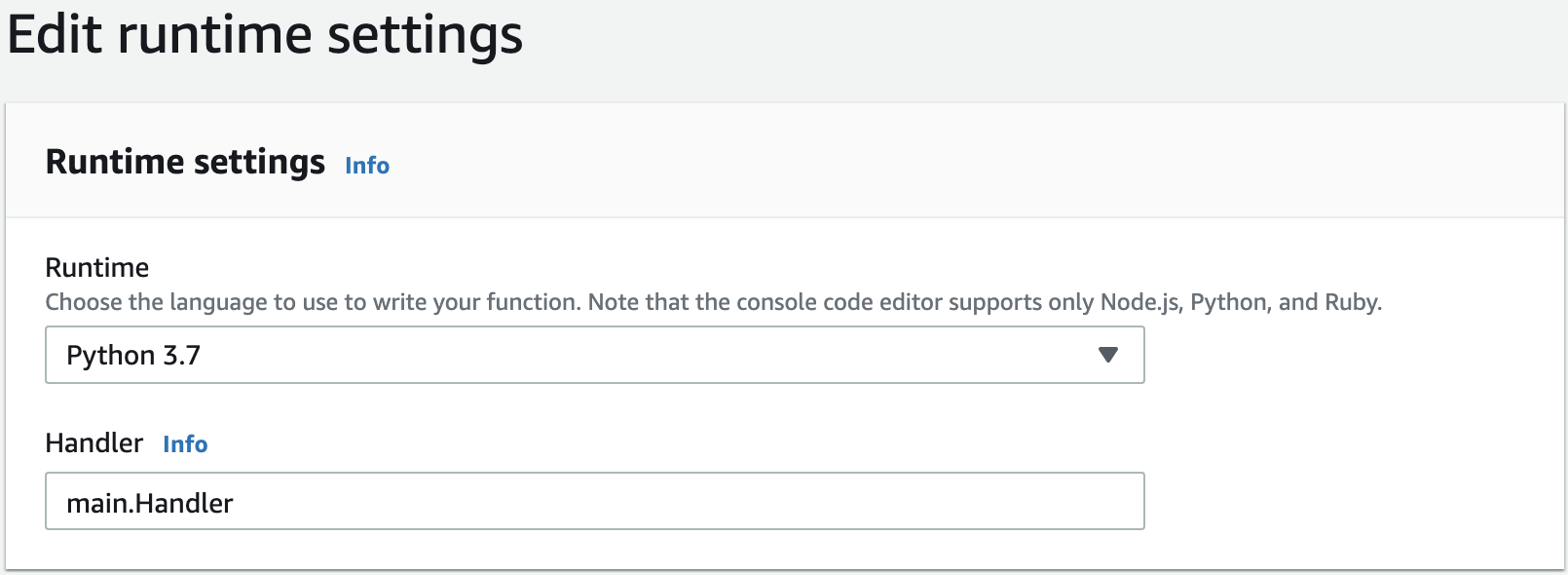
Step 2b: Write the Lambda Function
Change the filename from lambda_function.py to main.py and edit the runtime settings handler to main.Handler. Paste the code below for main.py.
from datetime import date
from io import TextIOWrapper
import gzip
import json
import random
import time
import urllib.parse
import os
import boto3
import requests
# Fill this out with your Project Token
PROJECT_TOKEN = ""
# Flush a batch once these limits are hit
EVENTS_PER_BATCH = 2000
BYTES_PER_BATCH = 2 * 1024 * 1024
# Adjust event timestamps of test data so that it appears recent in Mixpanel.
# NOTE: THIS IS JUST FOR DEMO PURPOSES.
# REPLACE THIS WITH YOUR OWN TRANSFORMS IN PRODUCTION.
def transform_to_event(line):
"""Convert a line of the file to a json string in Mixpanel's format."""
event = json.loads(line)
event["properties"]["time"] = int(date.today().strftime("%s"))
return json.dumps(event)
def flush(batch):
payload = gzip.compress("\n".join(batch).encode("utf-8"))
tries = 0
while True:
resp = requests.post(
"https://api.mixpanel.com/import",
params={"strict": "1"},
headers={
"Content-Type": "application/x-ndjson",
"Content-Encoding": "gzip",
"User-Agent": "mixpanel-s3"
},
auth=(PROJECT_TOKEN, ""),
data=payload,
)
if resp.status_code == 429 or resp.status_code >= 500:
time.sleep(min(2 ** tries, 60) + random.randint(1, 5))
tries += 1
continue
return resp
def Handler(event, context):
s3 = boto3.client('s3')
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
blob = s3.get_object(Bucket=bucket, Key=key)
if blob['ResponseMetadata']['HTTPHeaders']['content-type'] == 'application/x-gzip':
gzipped = gzip.GzipFile(None, 'rb', fileobj=blob['Body'])
data = TextIOWrapper(gzipped).read()
else:
data = blob['Body'].read().decode('utf-8').splitlines()
error = None
batch, batch_bytes = [], 0
for line in data:
# Here we assume each line is valid JSON representing a single Mixpanel event
# If lines are not in Mixpanel's format, apply any transformations here.
line = transform_to_event(line)
batch.append(line)
batch_bytes += len(line)
if len(batch) == EVENTS_PER_BATCH or batch_bytes >= BYTES_PER_BATCH:
resp = flush(batch)
batch, batch_bytes = [], 0
if resp.status_code != 200:
error = resp.json()
break
# Flush final batch
if batch and not error:
resp = flush(batch)
if resp.status_code != 200:
error = resp.json()
print(
json.dumps(
{
"message": "Import complete",
"request": event,
"success": error is None,
"first_error": error,
"severity": "INFO",
}
)
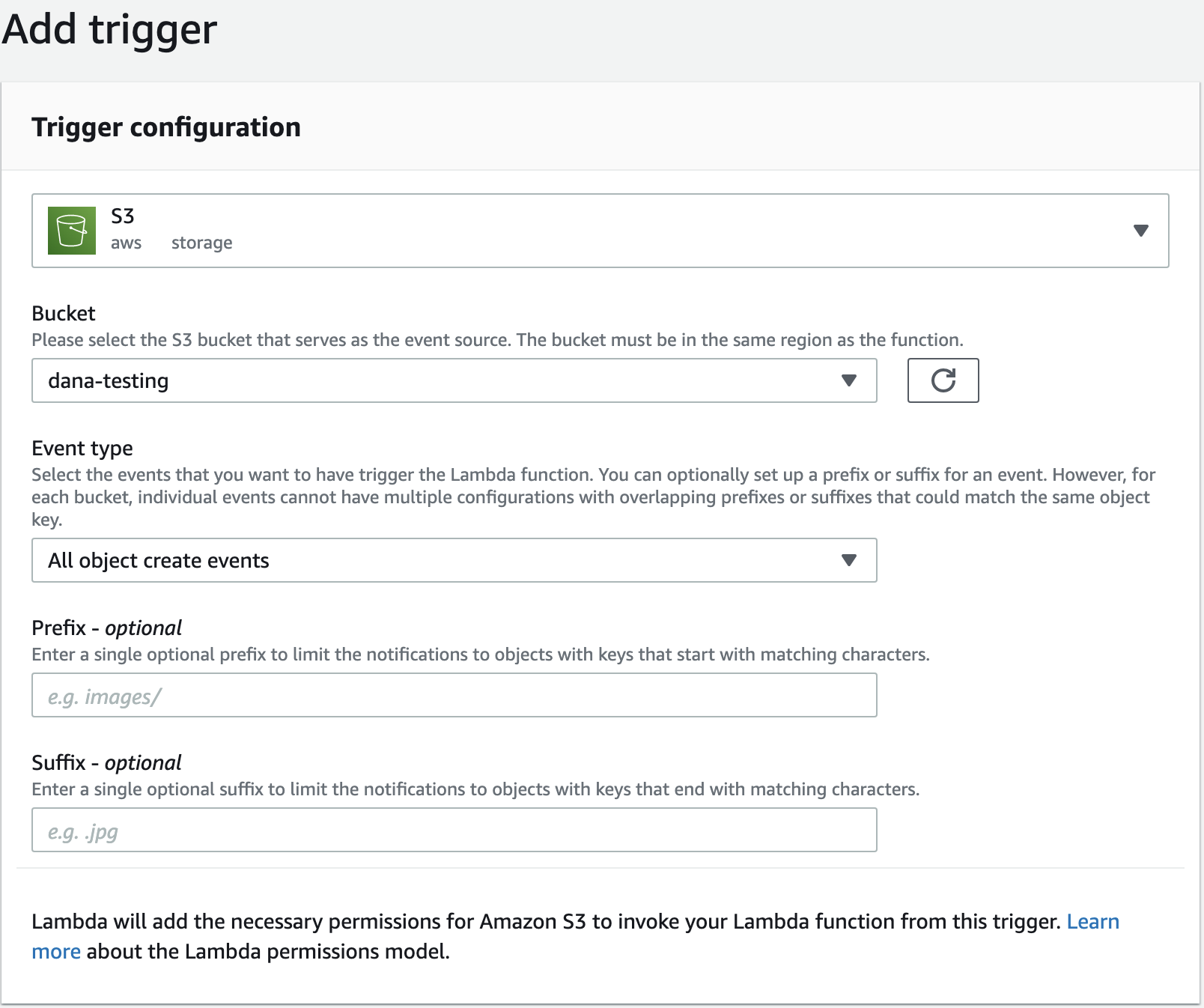
)Step 2c: Add Trigger
Add a trigger so that your Lambda function runs whenever a new object is added to your bucket by selecting Add trigger under Function Overview. You will want to use the bucket created in Step 2 and select All object create events.
Step 2d: Update Configurations and Deploy
Select Configuration > General Configuration > Edit.
- Change
Memoryto1024 MB. - Change
Timeoutto5 minutes.
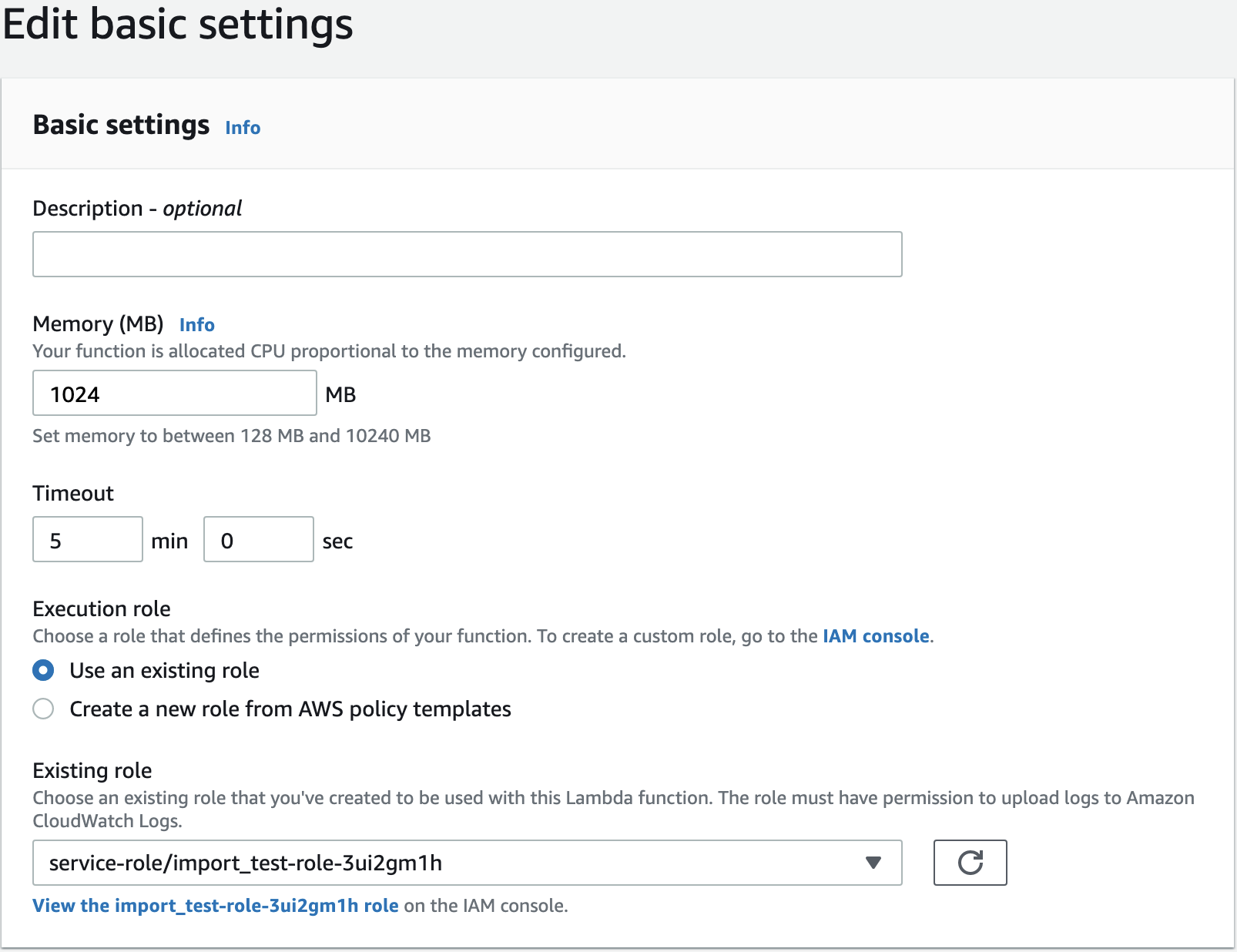
Click Versions > Publish New Version to deploy the function. At this point, any file you upload to the bucket will trigger an invocation of the function and an import into Mixpanel. Let’s test it out!
Step 3: Test with sample data and watch the logs
Let’s test the connection with some sample events. Run the following to copy them to your bucket, which will trigger the import:
gsutil cp cp gs://mixpanel-sample-data/10-events.json s3://your-s3-bucket/example.json
Monitor the logs of your Lambda Function; you should see an Import Complete log line within a minute.
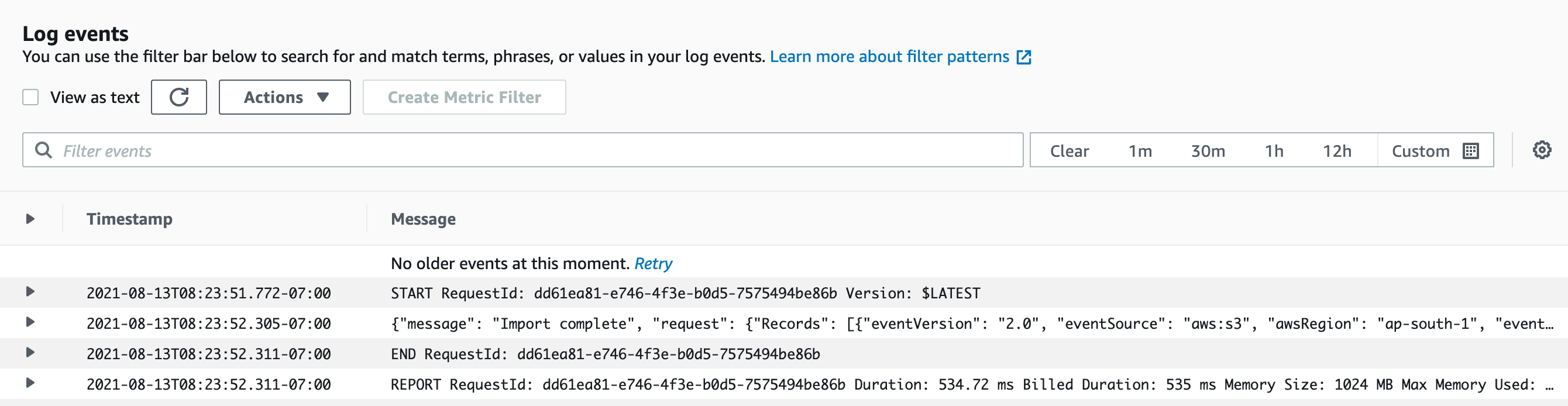
If you navigate to CloudWatch logs, you will see a more detailed log that includes the filename being imported and the first error encountered (if any).

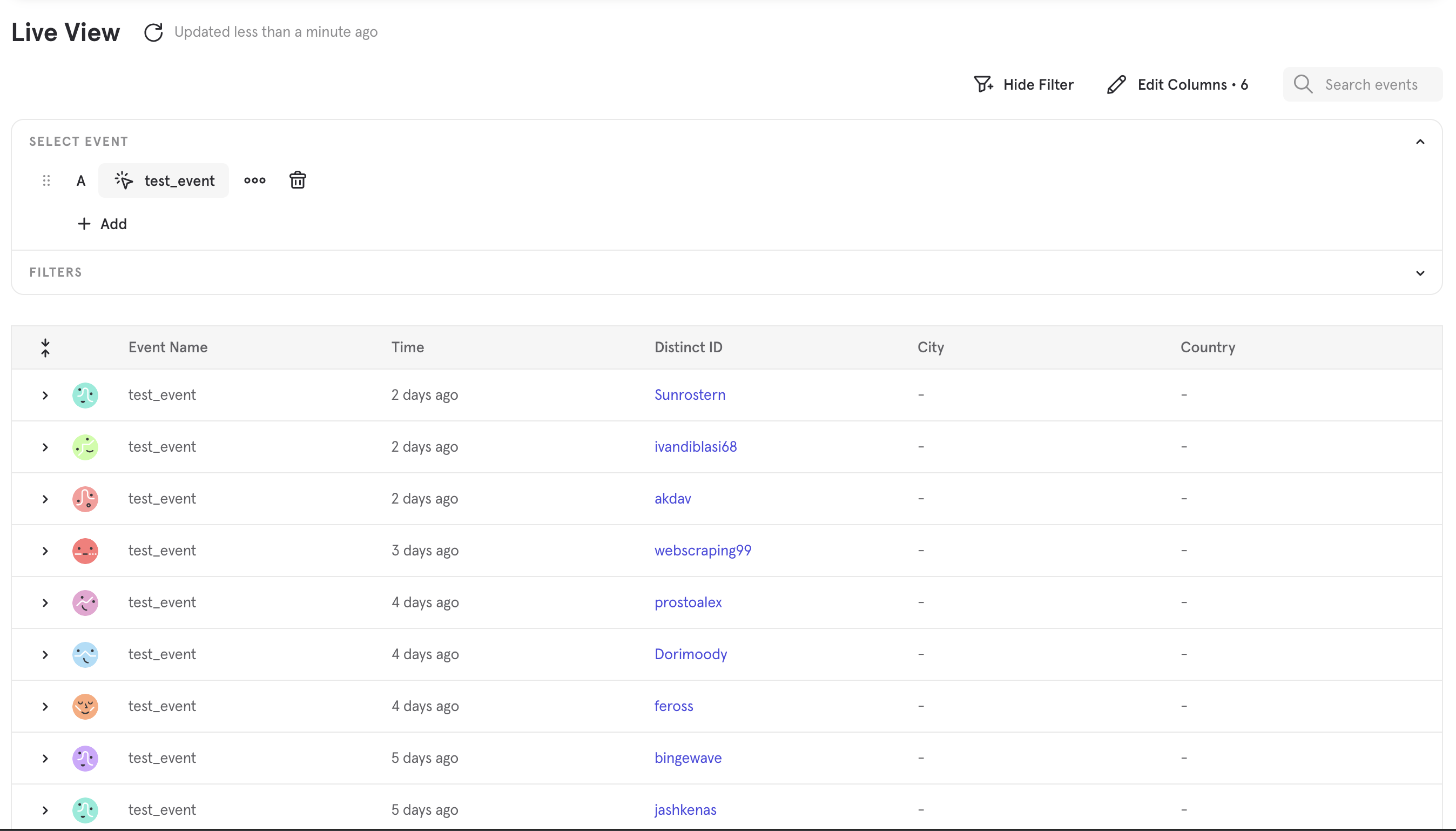
Finally, let’s confirm that the events made it into Mixpanel. Head to the Events page, pick test_event in the event picker, and you should see the events you just imported.
Step 4: Import more data
We’re now ready for an import of your own data. If your data is not already in the Mixpanel format, this is a good time to write a transformation step to run as part of the Lambda. We recommend testing locally as you iterate on your data transformation logic, as it’s much quicker than redeploying the Lambda. The Overview page has sample code and data to test locally.
Once you’re ready and have tested with a few small files, you can upload all the files for your import to your S3 bucket, and the import will kick off. This pipeline can be made recurring by uploading files to the S3 bucket periodically.
We recommend partitioning files in S3 to ~200MB of JSON for optimal performance.
Was this page useful?